杨宇 李鸣宇
(1.国网吉林省电力有限公司信息通信公司 吉林省长春市 130022)
(2.中国联通吉林省通信公司长春市分公司 吉林省长春市 130000)
图1所示为分布式计算,是当前被广泛使用的计算方法,其与集中式计算完全不同,是一种需要具备极强的计算能力才能够完成的计算方方式。如果需要计算同样的数据采用了集中式计算,那么就需要耗费大量的时间来完成此工作,无法适应当前快节奏的发展速度。但是使用分布式计算,则可以通过分解的方式让其能够用多台计算机完成相同总量的计算,实现节约计算时间的目标,而且还能够让其计算的效率得到大幅度的提升。
图1:分布式计算
分布式计算技术种类多样,不同的技术应用将会呈现出差异性的效果,本文将对其中最为常见的三种分布式计算技术进行对比分析,从不同的角度对分布式进行分析,从而探究各种不同的分布式计算技术所能够形成的功能效果。
其中主要是以网络计算、云计算以及志愿计算为代表。首先来讲,网络计算技术,是对主要涉及的资源形成合理的聚合分布效果,并对虚拟的组织结构提供支撑,从而搭建其更高质量的高层次有效计算服务。并能够形成相对较为稳定的网络拓扑结构,在计算任务完后,就能够直接退出系统,省略了众多中间繁琐应用环节,形成更加简易的计算作业方式。而志愿计算技术,能够更加自由的随意登入或登出系统,但是在系统灵活度有效提升的同时,任务完成的状况则难以及时的掌握,往往会出现任务未完成却杳无音信的状况。但由于计算任务未完成,将使当前计算节点的信誉度受到影响,在下次实施任务分配的环节中将会降低该节点的任务量。
云计算则是按照使用者的实际需求做好合理的按需分配,能够形成更加灵活且日常的运行服务效果,并以服务机制是镜像执行的方式实现异构。但是根据实际而言,网络计算、志愿计算以及云计算等方式都能够对异构资源提供相应支撑,而网络技术与志愿技术相较于云计算所形成的差别则是建立在用户使用效果基础上形成的。网络计算的异构会在中间件的作用下对其进行屏蔽,但相应的却能够为用户展示相应的异构信息,从而在中间件的作用下完成异构过程[2]。而志愿计算本身所能够产生的异构性影响不明显,仅需要志愿者提供反馈就能够完成异构,并无任何具体的设备以及系统的要求。
对比三种不同的分布式计算技术,可以发现分布式计算中的云计算技术已经呈现出进一步应用的良好效果,其降低了以往使用者有效投入工作的程度,仅需要选择相对应的技术类型,并支付相应费用就能够完成技术使用。而另外两种不同的计算技术应用则是建立在整体的系统设定中所形成的。云计算的分布式技术应用将完整的资源打造成更加分散的应用类型,有效提升了资源利用率。而网络计算以及志愿计算等均需要聚合资源重新应用,过程相对较为繁琐,并且在这样的过程中可能会造成资源丢失问题。
对比三种分布式计算技术,其中最为灵活的计算方式就是志愿计算,通过使用网络状态中的每一个闲置资源,向分支志愿计算结构传递相应的分割任务,随后对众多任务的处理结构进行整合后,形成完成的任务成果向上提交。在这一过程中无需网络计算的数据中心介入,更是无需应用云计算的云终端,仅仅是在host以及固定服务器的准备下就能够完成调度处理,相较于最原始的分布式计算技术本身存在着相一致的应用理念。
解决电力大数据储存以及计算需求,形成高性能的处理效果,在其中需要应用到分布式技术,并且仅仅是简单的技术应用难以形成良好的应用效果,则需要基于分布式技术构建起相应的系统模型,从而保障电力行业能够根据自身的需求特征,更加自主的使用到先进的分布式计算平台,满足生产运行过程中的大数据信息处理需求,结合相关数据库的应用,能够全面解决大量数据储存过程中的高吞吐以及并发瓶颈,从而全面解决电力大数据的计算难题。
2.1 分布式技术模型的构建
2.1.1 分布式文件系统
以Hadoop框架,构建基于电力大数据的海量储存需求下的系统结构,最为关键的就是其中的分布式文件系统的应用,建立在这一系统上以满足可扩展需求,从而保障能够实现更加良好的分布式储存作用。分布式文件系统在进行资源物理储存的时候,并不是知己连接本地的节点,而是采用计算机网络连接的方式与节点进行连接。而以往常见的分布式系统则是基于Key-Value所设计的建立在硬件中应用的运行系统,这样的分布式分建系统本身具有较为良好的实用性以及高容错性,因此,应用在大数据集中具有良好的优势。
分布式文件系统中负责储存元数据的则是独立运行的master,而基础信息数据的储存则是需要应用众多以block块所构建的slave结构[3]。借助于这样的结构,则能够在众多集群中部署系统应用,这样的集群数量高达成百上千,从而保障在分布式文件系统的作用下实现良好的扩展度,能够满足电力运行生产等众多业务过程中的数据传输与储存需求。并且,在这样的分布式文件系统的作用下,能够形成更加安全稳定的系统保障,在任何情况下都能够及时的解决故障问题。分布式文件系统中的文件副本能够保障数据储存处于安全状态,若当前系统在运行过程中出现任何的单点故障问题,都能够在最短时间当中恢复数据,通过数据备份保障数据安全,避免出现数据丢失的现象。
图2是以fastDF和nginx作为基础形成的分布式文件系统,在分布式文件技术不断发展的过程中,其被不断的规范化、标准化、流程化使其能够更加系统的完成计算目标,进而让分布式文件技术在构建系统的过程中形成了更加简单的模型,并且达成了一致性的设计效果,能够简化各种复杂的系统结构的同时,有效提升了并发量以及吞吐量。在这样的处理模型当中,通过多个不同的数据节点结合单一主控节点的基础上形成了分布式文件的集群。在集群中每一对应的节点均能够实现管理数据并且具备能够储存数据的功能,从而生成了众多数据节点的存在。而主控节点的主要功能则是对命名文件进行管理的同时,对能够申请文件访问的客户端服务器进行相应的调节。分布式文件系统中,所形成的内部运行机制,主要是能够将对应的数据文件进行分割处理,从而生成多个数据块的形式,在对应负责管理数据的节点上进行储存。为了能够更好的处理电力生产运行中庞大的数据量,建立的分布式并行计算系统其应用到分布式文件系统结构,结合计算机系统数据链的功能,完成数据的储存以及管理,从而能够实现更加安全可靠并且吞吐量相对较高的读写功能。
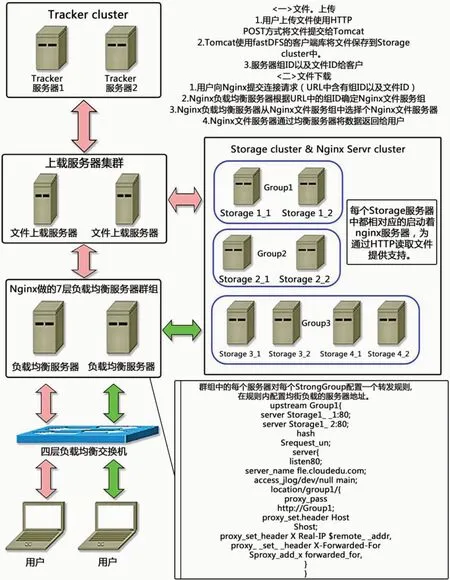
图2:分布式文件系统
2.1.2 并行计算
大规模的数据集实现更加稳定的并行计算要求,可建立在由Google提出的MapReduce软件模型的基础上,保障并行计算效果。创建分布式并行计算平台的过程中,引用当前软件架构,观察当前平台结构的整体构成,在相对应的体系中,MapReduce软件模型的应用能够形成相对更为简易的框架结构上,借助于这样的软件,从而能够向大量的商用机器平台所构成的集群中上传任务,以保障在数据并行运算的过程中具有相对较高的容错率。MapReduce软件模型的应用满足了数据量过于庞大时的处理需求,并且能够实现平台中多个任务的同步处理功能。SQL的复杂体现也能够在这样的软件架构下轻易的分解,并重新解析优化形成对应的处理任务,促使SQL能够实现平滑转换成为MapReduce的效果[4]。
并且在这样的分布式并行计算平台当中,对优化调度相关任务时同样可以借助于MapReduce软件模型实现。并行处理差异性业务数据的众多任务,优化系统资源结构,实现最大化利用计算系统。能够有效降低数据处理时间,解决了以往处理大量数据过程中的时间漫长问题。基于MapReduce软件模型所构建的并行计算平台,能够适应含有众多计算机结构的大规模集群中应用。并且基于实际而言,在对应的Map任务处理计算过程中,也能够实现基于Reduce任务的同步运行。二者运行时仅消耗单独的计算节点,从而有效扩充了同一时间可同步进行运算的任务量,保障具有较好的运算效率的同时,提升了运算能力表现。同时在MapReduce软件模型的作用下,每一对应的计算节点也能够当做数据储存节点应用,从而实现当前节点中数据的本地运算,有效避免了在实际当中由于数据量过于庞大在传输过程中造成网络堵塞而卡顿延缓计算的现象。
2.1.3 多维索引
在电力行业其数据是十分多样化的,通常在数据查询的时候都需要进行多维索引,才能够保证数据的全面性和实用性。当前,电力企业都在大规模的数据集上采用了多维索引的查询方式,从而让电力企业的数据查询工作的速度得到大幅度提升,而且还能够进一步提高数据的准确性和时效性,让电力企业的工作效率呈现跨越性的改变。
当前,多维数据查询主要分为两个阶段。第一个阶段就是Filter阶段。这一阶段主要是用来初步过滤数据信息的,给后续的数据筛选提供选择的候选集。通过初步的粗选,能够将数据信息快速地分类,按照要求缩小数据的范围,给后续筛选提供候选集。在经过第一阶段过滤之后,就是Refinement阶段,即细化查询阶段。在这一阶段,对第一阶段的数据进行了进一步的筛选,通过不断细化的方式在候选集中找出更加符合要求的结果,进而得出最终结果集。之后再将最终结果集中查询到的数据提供给工作人员。
多维索引最常用的索引就是二级索引。二级索引是在每个数据维度中建立的索引方式,根据以往查询的数据的次数和频率,建立一个常用的二级索引。这样,就可以在后续查询的过程中,利用二级索引作为查询的桥梁,扩宽数据查询的范围,更为明确地将信息数据定位出来,使整个查询速度提升起来,提高查询数据的效率[5]。
分布式技术的使用主要是建立了分布式平台,更替了传统的Hadoop平台,让索引模式不再局限于单列索引,而是能够多列同时进行索引,提高了查询系统的速度和准确度,还让查询的时候能够更加准确地定位出需要的信息。与此同时,分布式平台还彻底转变了以往的应用支持模式,使其能够支持更多应用,扩宽了数据查询的渠道。除了常见的二级索引之外,还引进了增强二级索引,以及互补聚簇索引三种索引。
2.2 总体框架
基于分布式技术所构建的大数据处理系统其本身则是为了适应智能电网发现下的众多数据处理要求所形成,通过分析电力行业的相关业务数据以及逻辑结构特征等,根据行业的先进经验,从而构建起良好的系统结构。在系统应用过程中,通过分布式技术的计算框架、MapReduce软件模型的并行计算开发,衍生出多为网络文件索引的可能性,从而能够适应电力大数据的运行要求。在数据查询以及重塑的过程中,能够实现基于SQL以及HQL的自动翻译以及数据自动更新等,确保能够形成功能性更加良好的系统结构。这样的分布式并行计算平台现已参与到我国众多的电力信息采集系统当中,促使原有信息采集系统功能有所提升,并解决了以往在运行过程中系统成本相对较高的问题[6]。
2.2.1 分布式储存环境
在分布式平台之中,其储存环境主要是以Hadoop框架为基础,并且在其上进行扩展优化得到的。分布式平台能够之间连接到终端,并且利用终端端口采集数据,使用并行ETL工具对采集来的数据进行整理分析,将档案类输出有序地储存起来进而方便后续的计算、查询。之后就可以使用平台中的查询引擎来支持平台的数据查询工作。然后还可以利用MapReduce并行环境让整个数据分析工作更加的高效。由此在多个辅助工具的协助下,形成更加良好的储存环境。
2.2.2 开发工具
分布式平台完成数据分析的功能需要各种各样的工具支持才能够完成高效查询计算的功能。当前分布式平台采用的主要有库表管理工具来让数据库有序地储存和分类数据;
索引管理工具提供更加高效的数据查询方式;
任务管理工具使查询更加的高效;
ETL管理工具优化数据查询和计算的速度;
SQL解析工具使数据查询更加的精准。在各个开发工具的协调使用下,使分布式计算平台的迁移和转换更有逻辑性,优化了平台的索引定义以及其他功能的性能。
2.2.3 计算环境
分布式采用的计算环境主要是MapReduce并行计算环境。运用MapReduce代码支撑平台的运行业务能力,让分布式平台能够更加高效地完成数据计算的工作,大大地提高了数据计算的速度。与此同时,MapReduce并行计算环境的使用液位并行ETL奠定了良好的环境基础,让其能够在有力的支撑之下,完成更大规模的数据处理工作,也让并行计算效果得到有力的保证。此外,这种环境的使用,也能够让整个平台的处理、分析以及计算功能得到全面的环境支持。
2.2.4 系统监控工具
对于分布式平台来说,其运行状态也需要人们加强重视。因此在分布式平台之中,必然会使用系统监控工具,让系统能够更加稳定地完成相关的数据管理工作,提高数据的可靠性。与此同时,通过全面的监控管理,分布式平台能够动态管理系统整体的运行情况,监控业务其他问题,以及在分布式系统中MapReduce任务的完成情况,从而让用户能够更加及时地完成运维管理工作,提高整个分布式平台的数据处理可靠性,更加快速完成数据处理工作。
2.2.5 运行调度工具
当前分布式平台在进行运行的时候,难免会随着时间的推移出现问题。因此相关人员需要做好调度工作,确保在进行任务规划的时候,能够充分地利用MapReduce等工具对其新房进行合理地使用,不会因为没有调度工具导致任务维护工作存在问题。与此同时,还应该重视其不同任务之间的联系,确保其存在足够的依赖性和关联性,进而确保分布式平台的执行任务的时候能够更加的准确,提高任务完成的正确度。与此同时,还能够让平台运行更加的稳定[7]。
2.2.6 并行ETL工具
并行ETL工具主要是在分布式平台中实现抽取数据,并进行转换和加载功能的工具。并行RTL工具的作用是,为关系型数据库的建立提供有力的支持,让分布式文件系统中的数据能够更加有序地进行储存。与此同时,其也是支持数据的导入和导出的关键部分。它能够让分布式平台更加高效地完成数据管理工作,更加准确的调度管理的作用,提高监控管理的力度,使其能够更加高效准确的运行平台中的脚步,促进每一个功能的稳定性,提高平台的性能。
2.2.7 业务应用服务接口
分布式平台最终的目的还是要给用户提供服务,业务应用的服务接口是必不可少的。在分布式平台之中,大多采用服务的形式给外部的其他系统提供服务接口,满足其不同的要求。比如复杂化的数据查询业务,较大规模的数据计算业务等等。通过业务应用接口的支持,让整个平台能够更大地发挥出其功能,并且还能够使每一个功能都得到了有效地利用,满足用户多样化的需求,达到高效率、多样化、全方位的服务目标。
综上所述,本文提出的使用分布式技术来优化电力大数据高性能处理工作的方案十分有效。通过对电力大数据的概念的讲述,对分布式技术的对比分析,以及将分布式技术运用在电力大数据之中的具体情况的研究,全面地证明了分布式技术的可行性。
猜你喜欢 储存分布式节点 储存聊天记录用掉两个半三峡水电站电量军事文摘(2022年16期)2022-08-24分区域的树型多链的无线传感器网络路由算法现代电子技术(2022年4期)2022-02-21居民分布式储能系统对电网削峰填谷效果分析科学与财富(2021年35期)2021-05-10基于移动汇聚节点和分簇的改进节能路由算法卫星电视与宽带多媒体(2020年7期)2020-06-19基于Paxos的分布式一致性算法的实现与优化华东师范大学学报(自然科学版)(2019年5期)2019-11-11基于点权的混合K-shell关键节点识别方法华东师范大学学报(自然科学版)(2019年3期)2019-06-24松鼠怎样储存食物小猕猴学习画刊(2016年12期)2017-01-05异质性储存服务器及其档案储存方法科技创新导报(2016年4期)2016-11-19浅谈基于P2P的网络教学系统节点信息收集算法职业·下旬(2009年7期)2009-01-20