蔡圣杰,郑成勇,陈伟杰
(五邑大学 数学与计算科学学院,广东 江门 529020)
随着对环境治理的持续投入,我国绿地面积显著提升,林地物种也越来越丰富,如何准确高效地识别植物便成为亟待解决的问题. 由于硬件性能的提高,基于神经网络的树叶分类方法也逐渐流行. 魏书伟等提出了并行残差卷积神经网络和加入残差学习的Alexnet网络,精确率达到90%以上[1].针对复杂背景中的叶片图像,Yang等提出了基于Mask区域的卷积神经网络,其平均分类误差为1.15%[2]. Shivali等采用健康和病株叶片数据混合的形式在预训练的AlexNet上迁移学习,相较于支持向量机准确率提升1%以上[3]. 除了理论上的发展,基于神经网络的树叶分类算法已应用于烟叶[4]、芒果叶[5]、草药[6]等的分类中.
然而上述工作大多应用于较少类别数据集的分类任务,基于种类较多的数据集上的分类工作比较少. 而其中仅少数分类准确率可达到95%,但是这些模型复杂度较高,运行速度不理想. 为此,本文提出一种基于残差网络迁移学习的树叶分类算法,以期满足现实分类任务的需求.
1.1 残差神经网络
残差神经网络[7](Residual Network,ResNet)由微软研究院的何恺明等人于2015年提出. 在此之前,VGG[8]模型中的卷积层达到了19层,GoogLeNet[9]模型中的卷积层更是达到了22层. 随着网络层数增加,训练集损失逐渐降低,然后趋于平稳;
当继续增加网络深度时,训练集损失反而会增大,网络发生了退化现象. 而当网络退化时,浅层网络能达到比深层网络更好的训练效果. 这时如果将低层特征传到高层,那么理论上效果至少不比浅层的网络效果差,因此提出残差块的结构. 图1给出了普通块(图1-a)和残差块(图1-b)的对比示意图。增添一条单位映射即可将普通块变为残差块. 单位映射确保了N+1层的网络一定比N层的网络包含更多信息,因此基于使用单位映射连接不同层的思想,残差网络应运而生.
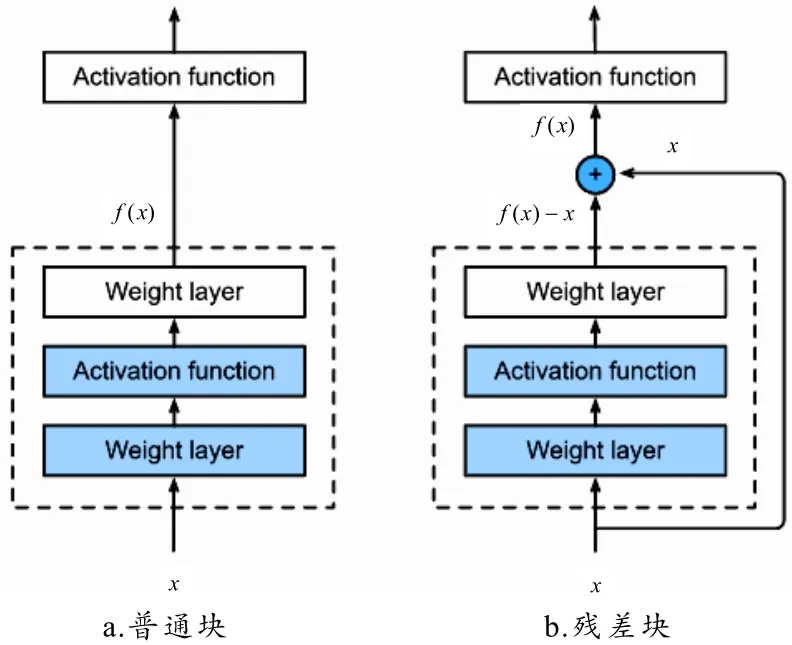
图1 一个普通块和一个残差块
残差网络模型继承了之前网络的优点,并将普通块替换为残差块,构造网络. 以ResNet18为例,网络分为5个阶段,如图2所示:第一个阶段是过去网络中常用的起始设计;
第二至五阶段由数个残差块组成. 最终通过全局平均汇聚层与全连接层输出类别. 网络总计18个卷积层(包含全连接层),因此命名网络为ResNet18.
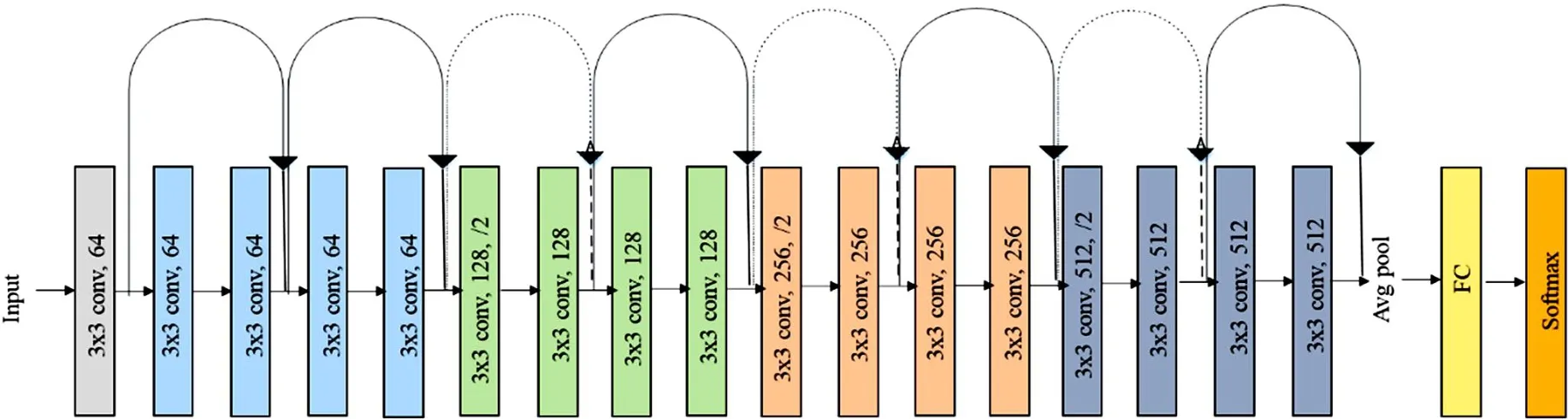
图2 ResNet18的结构
通过增减残差块的数量构造了以卷积层数命名的ResNet18、ResNet34、ResNet50、ResNet101、ResNet152. 它们既有相同点又有不同点. 其第一阶段均为一个卷积层和一个汇聚层,中间均有4个阶段,最后两层均是全局平均汇聚层和全连接层;
不同之处在于4个阶段中的残差块数量. 随着更多更新的结构出现,一些新技术也被更新进残差网络模型.
1.2 迁移学习
迁移学习是指从源数据集中学到的知识迁移到目标数据集. 即使源数据集与目标数据集在内容、构成上不尽相同,但在源数据集中学到的特征提取能力仍能识别出边缘、纹理、形状以及复杂组合. 这些类似的功能都将有助于识别目标数据集中的物体. 因此使用已在源数据集上训练完成的模型,在规模不大的目标数据集上稍作训练即可识别目标数据集中的物体. 这一方法不仅使制作数据集的成本大大降低,同时也使训练模型的时间成本大大降低.
算法流程如图3所示. 首先使用大规模数据集对主干网络进行训练,保留其各节点的权重,将主干加以改造成为适合树叶数据集的结构. 然后为了提升模型分类精度,将模型放在树叶数据集上学习之前,先将这些图片进行预处理. 最后使用树叶数据集在最终模型上进行迁移学习,以得到可以对较多类别树叶进行分类的模型.

图3 算法流程
2.1 预训练及结构改造
利用残差网络的原始结构在ImageNet上进行预训练至收敛. 之后保留网络结构与各个节点的权重,改造成为需要的模型. 基于ImageNet预训练的ResNet系列模型,其输出是1 000个类别. 因此需要将模型最后一层替换为节点数是类别数的全连接层,或在其后增加若干个全连接层,使模型在结构上具备树叶分类能力.
2.2 预处理及迁移学习
对数据的预处理是为了提升模型分类效果. 本文算法中的预处理主要是出于增加样本多样性的考虑. 对原始图片进行数据增强,包括但不限于垂直翻转、水平翻转、随机剪裁、中心剪裁、颜色波动、高宽比变化等,再进行标准化. 数据增强的操作仅针对训练集使用,目的是增强样本之间的差异性,提高模型的鲁棒性,降低过拟合的可能.
改造层的权重初始化后需使用目标数据集对其进行训练. 使用预处理后的图片对预训练后的改造模型进行迁移学习. 在迁移学习中有不同的学习策略:模型主干参数可以全部冻结,只训练改造层的权重;
也可以让主干与改造层在数据集上一同学习新的权重,最终实现高效树叶分类的目的.
本文实验全部在Colab平台上实现,目标数据集存放在Google云端硬盘,平台提供25 GB内存、147 GB磁盘以及Tesla P100-PCIE-16GB的GPU. 因为Colab预装了很多矩阵运算的包,并且该平台下载未预装的包时速度较快,同时能避开因系统不同而造成的装包错误,所以实验选择在该平台上进行实现. 实验中所使用的运算包主要有:math、shutil、pandas、mxnet、d2l.
实验对比了5个ResNet模型和2个VGG模型在数据集上的误差与速度. ResNet系列中从轻量级到重量级分别有ResNet18、ResNet34、ResNet50,ResNet101以及ResNet152. VGG16、VGG19与其中ResNet101和ResNet152属于重量级模型,难以满足实时要求. 而ResNet18和ResNet34属于轻量级模型,支持在便携设备上使用,但因其复杂度较低,所以精度也无法达到预期. 因此常用的是复杂度和速度都适中的ResNet50.
实验所用数据集为Kaggle上一项树叶分类竞赛的树叶数据集,其拥有176类形态各异的树叶,其中训练样本16 518个,验证样本1 835个,测试样本8 800个.
3.1 不同的数据增强效果
实际任务中常用的数据增强操作有: 垂直翻转、水平翻转、旋转、随机剪裁、中心剪裁、五点剪裁、颜色波动、高宽比变化、叠加混合、剪切混合、透视、伽马变换等. 实验中使用的操作有水平翻转、竖直翻转、裁剪、随机颜色波动、随机长宽比拉伸. 水平和竖直翻转概率的取值为0和0.5;
裁剪方式分为中心裁剪和随机裁剪,取值范围是0~1;
颜色波动的取值范围为0~1;
随机长宽比拉伸的取值范围是1/2~2到5/6~6/5. 根据Leaves数据集的特点,对图像进行不同程度的数据增强,并进行对比实验.
水平翻转与垂直翻转都可以增加数据的多样性,提高模型泛化性能. 然而如图4所示,水平翻转比无翻转降低了验证误差,但垂直翻转和垂直水平翻转都提高了验证误差.因为对于一些物体来说,经过垂直翻转后的形象在实际生活中并不存在(例如汽车、信号灯、房屋等),因此有些物体不适宜垂直翻转.
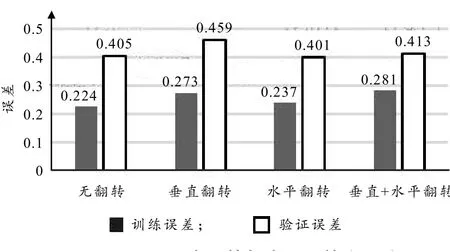
图4 垂直翻转与水平翻转交叉验证
裁剪的目的是适当放大待识别物体,使其在图片中更突出,去除一定的无关背景,在一定程度上增加物体的多样性. 如图5所示,在使用中心剪裁时验证误差逐渐增大. 使用随机剪裁时,当参数设为0.9时验证误差最小,随后缓慢增大. 所以,选择随机剪裁图片大小的90%左右作为输入较为合适,因为数据集中的树叶并不全位于图片中心且背景简单. 因此裁剪的策略主要依据数据集里的图片类型而定. 若待识别物体基本位于图片中心位置时,则可以选择中心剪裁,中心剪裁的参数选择则依据数据集里待识别物体占图片的比例来决定. 若数据集中待识别物体并不是都位于图片中心则可以选择随机剪裁或五点剪裁,随机剪裁的参数选择与中心剪裁的参数选择方法一致.
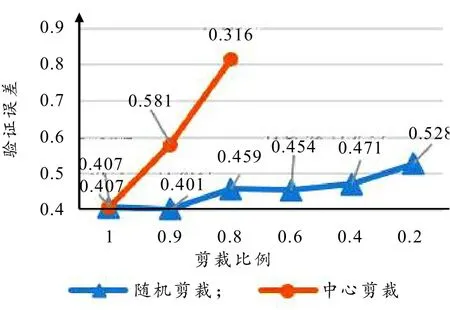
图5 随机剪裁与中心剪裁交叉验证
颜色波动包含3个方面:亮度、对比度和饱和度. 由于感光元件和拍摄环境等不同,同一类物体在照片中的亮度、对比度、饱和度甚至颜色都会有所不同. 因此在训练模型时,增加适当的颜色波动,有助于增强模型的泛化性能. 但是波动范围太大时,图片会发生过曝或欠曝等问题,以至于图片难以识别. 颜色波动的取值范围为0~1,如图6所示,一般选择0.1~0.4的值. 此处当参数设为0.2时验证误差最小,当参数大于0.4时,验证误差急剧增大.
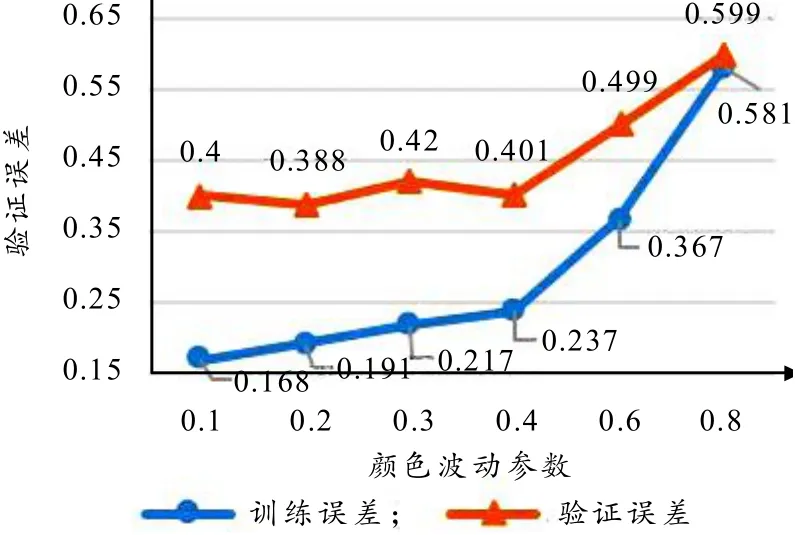
图6 颜色波动参数交叉验证
高宽比拉伸是在图片中随机选取一个高宽比在参数范围之内的子区域,最后被拉伸为标准尺寸作为输入. 这在一定程度上可以增强模型对物体的认知能力,但是拉伸程度也不宜过大,否则可能会导致模型因为学习了拉伸比过大的图片后反而对正常尺寸物体无法识别. 如图7所示,轻微拉伸到剧烈拉伸,验证误差先减小后增大,验证误差选取拉伸比在3/4~4/3时可有效降低模型的分类误差.
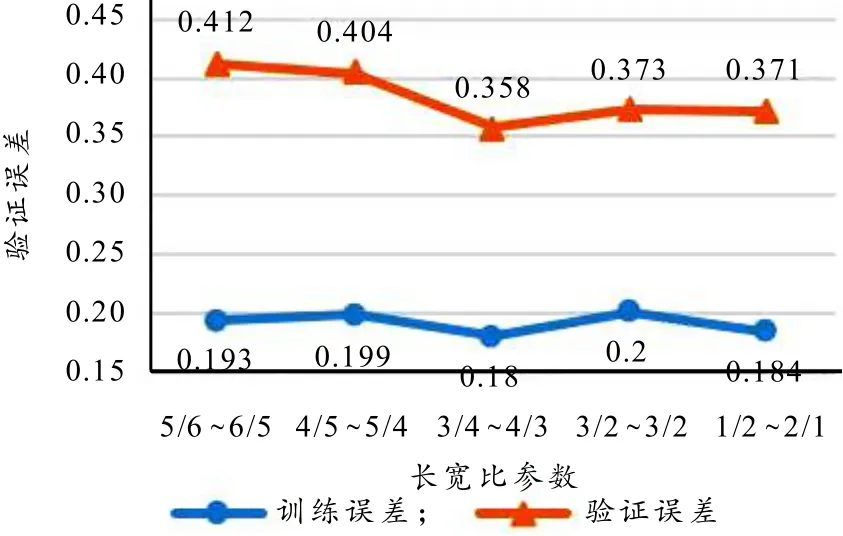
图7 长宽比拉伸参数交叉验证
3.2 参数稳定性验证
对随机剪裁参数和颜色波动参数进行网格搜索,如图8所示,未出现较大波动区域. 随机剪裁参数设为0.8~0.9,颜色波动参数设为0.1~0.2,可见模型较为稳定,准确率较高.
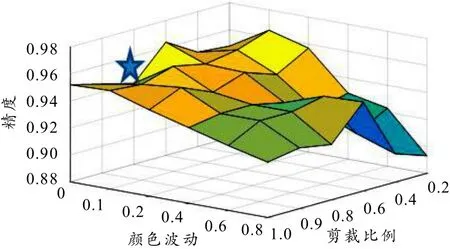
图8 随机剪裁与颜色波动参数网格
同样对随机剪裁和长宽比参数进行网格搜索,如图9所示,未出现较大波动区域. 最优区域出现在随机剪裁0.85、长宽比3/4~4/3附近.
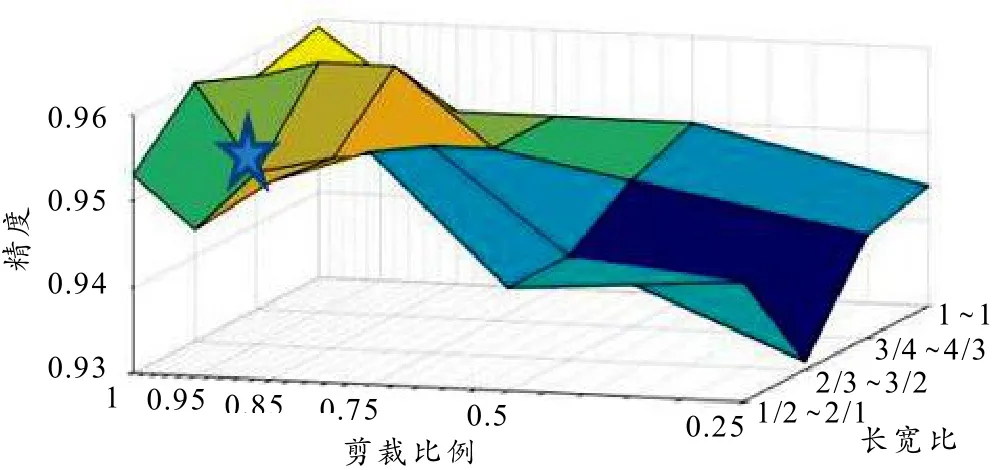
图9 随机剪裁与长宽比参数网格
3.3 改造层与迁移学习策略
将ResNet50的主干部分参数冻结,在其末尾层之后再添加新的全连接层,将原本1 000类的输出映射到目标数据集的类别数(176类);
或是主干参数解冻,将最后一层替换为需要的全连接层. 不同的全连接层设计将有不同的效果,对比不同结构、不同学习策略对模型准确率与效率的影响.
主干冻结模型结构如图10所示:模型主干参数冻结;
A)在主干之后增添一个256节点的全连接层、B)主干之后增添一个512节点的全连接层、C)主干之后增添一个512节点的全连接层和一个256节点的全连接层;
最后使用176节点的全连接层作为输出层. 图11给出了3种全连接层改造方案的实验对比结果. 从图11可以看出,改造层越丰富,网络的学习能力就越强,训练误差和验证迁移学习策略的对比实验如图12所示:替换末尾层为176节点的全连接层,对比冻结主干仅通过改造层进一步学习与解冻主干模型整体一同进一步学习的效果差异. 实验结果如图13所示,解冻方案的效果在误差和准确率上均优于冻结策略.

图10 主干冻结时3种全连接层改造方案
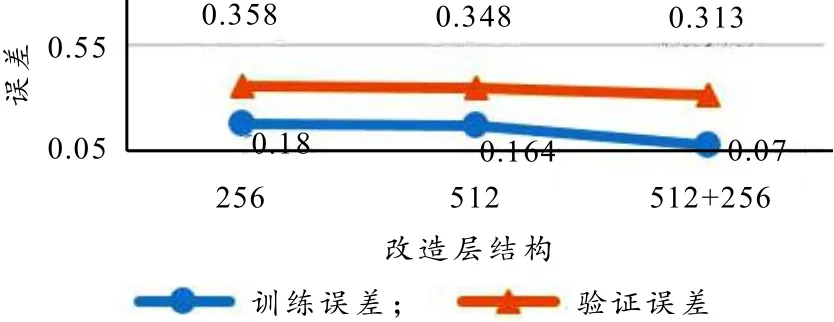
图11 3种全连接层改造方案的实验对比结果
图12 迁移学习策略对比图
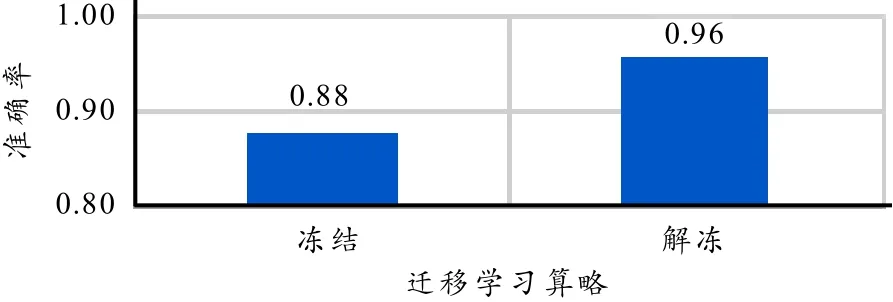
图13 迁移学习策略对比实验结果
3.4 不同的模型
鉴于整体迁移学习能大幅提高模型分类能力,本文对比了使用不同量级模型整体迁移学习的分类情况. 各个模型的超参数参考ResNet50中的超参数进行微调. 实验结果如图14所示,准确率较高的网络分布在靠右的位置,其中ResNet101的准确率最高,达到了96.3%. ResNet152虽然层数更多,但在准确度上与ResNet50相近;
在速度方面,随着残差网络卷积层的增多,速度越来越慢. 速度最快的ResNet18每秒可以处理图片212.2帧,其准确率仍有95.6%. 与残差网络相比,VGG16在准确率与速度方面都不占优.
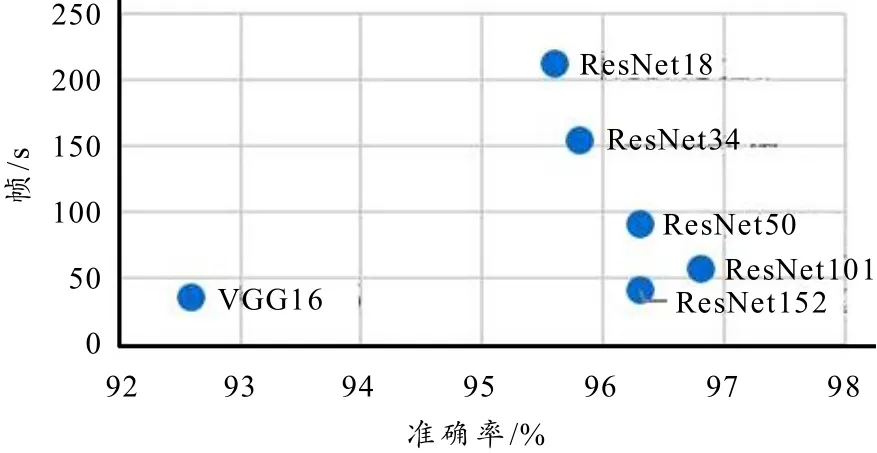
图14 解冻主干时模型精确度与效率
因此,当整个模型参数都进行学习时,可根据实际任务的不同需求选择合适的模型. 若实际任务需要更高的精度,则选择ResNet101更好;
若实际任务需要更快的分类速度,则选择ResNet18更佳.
由以上的实验结果及分析,得到如下3个方面的结论:1)模型的选择既不是越快越好(轻量级),也不是层数越多越好(重量级),而是需要选择与数据集复杂度相适应的模型进行训练. 模型过轻时,虽然训练时间比较短,但是模型的学习能力不足以匹配数据集的复杂程度,因此精度也大打折扣;
模型过重时,虽然其学习能力非常强,但是不仅训练速度十分缓慢,而且很大可能出现过拟合的情况,从而使其泛化性能不强、精度不高;
2)数据增强并非越多越好. 数据增强需要根据数据集的特点加以选择. 例如:一般情况下水平翻转都有助于提高精度,而垂直翻转对于一些数据集来说却并不合适,甚至会降低精度. 同理,选择随机裁剪或中心裁剪也要根据数据集中的图片构图情况来决定. 总的来说,数据增强还是有助于提高模型的分类精度的;
3)迁移学习中,深度网络主干作为特征提取器时,多层感知机的层数与节点数也应与目标数据集的复杂度匹配. 当在深度网络主干后设计契合目标数据集种类的全连接层时,新的全连接层与主干形成了一个新的整体网络模型.新模型中的参数在目标数据集上进行迁移学习,从而达到对目标数据集的分类目标. 在树叶数据集上,不冻结主干的迁移学习比冻结主干的迁移学习效果要好很多;
4)基于ResNet18的树叶分类方法是轻量级网络,可在便携设备上实现部署,同时满足了精度要求和速度要求,可应用于实际护林工作.
实验有待提高之处有3个方面:1)数据集中的背景比较简单,干扰因素较少,未采取室外复杂环境背景进行实验;
2)地球植物种类众多,176类相对来说还是太少,数据集类别增多势必会带给模型新的挑战;
3)信息量不足,实际的分类需求并不仅仅只需要物种名称,往往还需要其他相关信息. 未来可以尝试复杂背景下针对更多类别树叶的分类工作.